论文解读
论文提到的DeepFM网络结构图如下所示,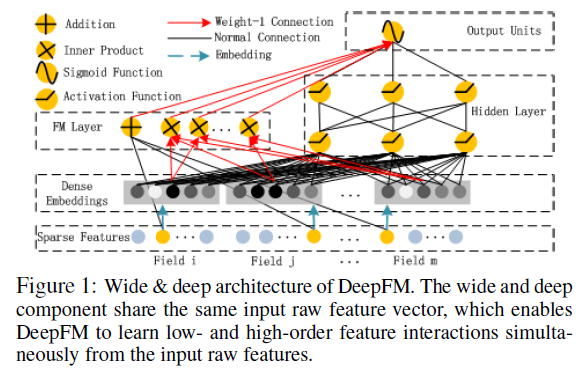
该算法主要特点如下:
- 网络结构分为FM部分和Deep部分
- FM主要做特征组合,包括一阶特征和二阶特征
- Deep部分用来对embedding后的表示提取高纬特征
- 两部分直接共享特征embedding权重参数
- 最后将FM和Deep部分的输出进行concat采用sigmod函数进行输出
- 不需要人工设计特征组合,网络end to end学习组合特征
FM Part
FM(Factorization Machine)模型主要是用来获取组合特征,模型如下:
上面是采用向量形式进行表示,这里我们沿用FM原论文中的表示形式,
其中,$n$表示特征个数,$V_i$表示$k$维特征隐向量。下面我们来对上面这个公式具体推到,获得最终计算形式,
上式中$\sum_{i=1}^{n}\sum_{j=i+1}^n
对称矩阵A如下:
对称矩阵A的上三角表示形式为:
根据对称矩阵的性质,上三角矩阵的元素和等于矩阵所有元素和减去对角线之和的一半,所以FM公式二阶特征可以做如下转换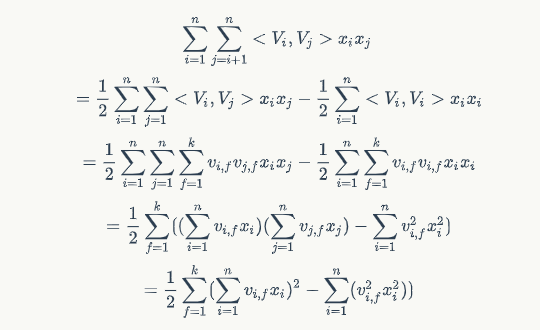
因此最终的FM部分的公式变成如下形式
对公式进行符号表示,便于后续实现时进行说明,
上述形式也是在进行算法实现时所采用的的形式.
Deep Part
论文中deep部分是将embedding后的结果联合一阶特征$A_1$ 和二阶特征进行concat,送入DNN,计算公式如下
其中$|H|$表示DNN的网络层数,$a$表示上一层网络输出。
数据集准备及分析
模型实现采用kaggle 比赛中公开数据集。数据情况如下
- 数据总共有40个字段,字段间用tab键进行分开
- 第一个字段,即Field0 表示$Label$ 值为1或0,表示该ad被点击与否
- I1-I13,共13个字段表示数值字段,通常一些计数值
- C14-I39,共26个字段为categoryical 字段,即离散类别型特征
- 字段值不存在时,默认为空
- 所以字段进行了脱敏,没有具体实际指代含义
实现逻辑和流程
整个系统实现逻辑流程如图所示。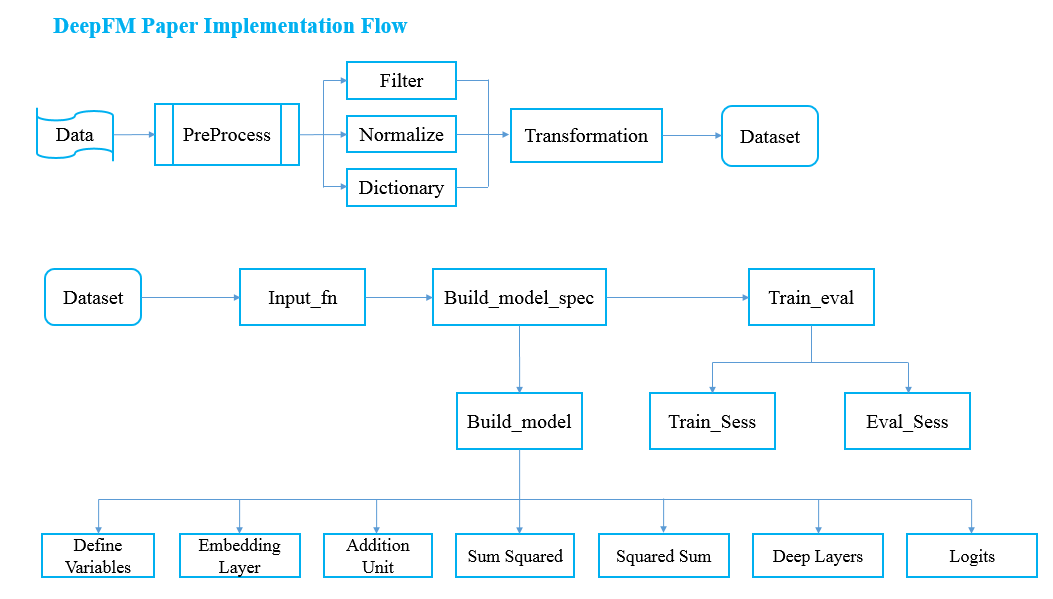
数据处理
数据处理这里采用主要原则是,将所有数据集中的所有值都当成特征值进行处理,对于连续值,将整个字段作为一个特征,这样所有的特征值都存在于同一个字典中进行编码。(原论文采用此种方式处理,至于初衷还在思考中),按照论文所说,需要对每个categoryical字段单独进行one-hot这样做下来,单条encode后的数据维度会很大,这取决于每个field的bucket切分,处理起来较麻烦,这也许是作者采用前述方法的主要原因。这里我在进行算法实现时对数据做如下处理:
- 对continuous field, 即数据中的数值:
- normalize到(0,1),采用该区间内$norm=\frac{val-min}{max-min}$,首先寻找每个字段中的最大值和最小值,存放在字典中
- id编码,对于连续性或者数值型字段,将整个字段作为一个feature,编码为一个id,value就是归一化后的值
- categorical field ,离散型字段
- 在每个字段中统计每个value出现的频率,通过设定频率阈值进行过滤,生成字段对应字典,
- id编码,将所有字段中的值统一到同一个字典中进行编码,id是在连续字段编码基础上进行累加,
数据处理结果
采用以上方式对数据进行处理,最终形成的数据格式是,, 数据以tab为分割符有三个字段,第一个字段为feature value是数据归一化后的值或者是one-hot后的1,第二个字段是前一个字段对应的feature id, 第三个字段为该条数据的label
生成字典格式如下:1
2
3
4
5
6
7
8
9
10feat_dict = {
"1": 0,
"2": 1,
"14": {
"68fd1e64": 2,
"287e684f": 3,
"8cf07265": 4},
"feat_size": 121641,
"<UNK>": 121640
}按照以上方式对数据进行转换,遵照原始数据的顺序按照$8:1:1$拆分为train/dev/test数据集,用于做模型训练和测试。
数据处理部分code可以在data_reader.py中找到,代码采用multi-thread对数据进行处理,因为文件特别大,采用多进程来提高处理速度,对于categorical字段的过滤阈值,是通过统计每个字段中值的频率,进行设定,也可以将所有字段设置为同一个阈值,比如频次为10等。
思考
- 对于categoryical特征进行处理方式,按照原文的思路是对所有离散特征放在一起进行one-hot,和每个字段单独one-hot进行处理,这两种方式对最终模型效果是否有较大影响?用LR做排序的时候,处理对象也是有多大40多个字段包含连续和离散,处理方式是将所有字段都转换为类别型特征,单独进行one-hot encoding。我考虑到如果每个字段单独one-hot,也就需要后面单独创建embedding进行lookup,如果有20个字段那就需要20个tabel进行学习,在实现上不便利,而且每个table值都是需要进行学习的。
系统设计
input_fn
该模块主要作用是对已经转换为value sequence, value id sequence, label数据,使用$tf.dataset.API$ 进行pipeline处理,最终输出内容为1
2
3
4
5
6inputs = {
"values": values,
"indices": indices,
"labels": tf.reshape(labels, shape=[-1, 1]),
"iterator_init_op": init_op
}主要的处理步骤:
- 利用tf.dataset.api,这里采用的是tf.data.TextLineDataset从数据文件中读取数据,返回结果是tf.dataset 形式
- 利用dataset.map()操作对读入的每行数据进行parse,这里parse的结果有三部分,values, indices, labels, 在进行parse的同时,需要对数据进行padding,这里根据字段个数,sequence length 是39,对于不足该长度的用0进行padding,indices用padding_index 代替,最终保证每个数据长度都是一致;还有一种是直接利用dataset.padding_batch,根据batch中最长的sequence长度对其他数据进行padding
创建batches iterator, 根据是否处于”train” or “test”决定是否对数据进行随机打乱,代码如下:
1
2
3dataset = dataset.shuffle(buffer_size=buffer_size)
.batch(batch_size)
.prefetch(1) # always keep one batch ready to serve创建迭代器,拆解batch tensor作为输入, 制作inputs字典
1
2
3iterator = dataset.make_initializable_iterator()
init_op = iterator.initializer
(values, indices, labels) = iterator.get_next()
以上是数据处理pipeline,充分利用tf的数据处理能力,可以作为通用处理模式,对任意算法任务建立类似的处理逻辑,需要根据具体任务修改parse函数,这是input_fn实现。
build_model
该模块主要用来构造DeepFM网络模型, 为了能够支持单条数据的inference,在构建的模型时,只采用三个函数,$inference$和$loss$,网络搭建在$inference$函数中实现,$loss$用来计算模型损失。
网络搭建的主要过程如下(这里尽量名字与code中一致):
| Variable | Input Shape | output Shape | Notes |
|---|---|---|---|
| feature_embedding | [feat_size, emb_size] | None | sparse feature to dense feature |
| feature_bias | [feat_size, 1] | None | weight of order-1 |
| DNN | [field_size*emb_size, hidden_layer[0]] | Full Connect |
这里只是简单列了主要的一些变量,详细的请参考code
build_model_spec
该模块主要是模型设定,model specification 会包括模型训练或预测过程中各种operator、loss、评估指标、输入输出tensor等,在本实现中分两种情况来创建model specification。train mode
1
2
3
4
5
6
7
8
9
10model_spec['loss'] = loss
model_spec['accuracy'] = acc
model_spec['metrics_init_op'] = metrics_init_op
model_spec['metrics'] = metrics
model_spec['update_metrics'] = update_metrics_op
model_spec['summary_op'] = tf.summary.merge_all()
model_spec['train_op'] = train_op
model_spec['variable_init_op'] = variable_init_op
model_spec['prediction'] = prediction
model_spec['score'] = scoreeval mode
1
2
3
4
5
6
7
8
9model_spec['loss'] = loss
model_spec['accuracy'] = accuracy
model_spec['metrics_init_op'] = metrics_init_op
model_spec['metrics'] = metrics
model_spec['update_metrics'] = update_metrics_op
model_spec['summary_op'] = tf.summary.merge_all()
model_spec['variable_init_op'] = variable_init_op
model_spec['prediction'] = prediction
model_spec['score'] = score
具体每个op代表的含义可以查看代码model_fn.py
train_evaluate
该模块主要是定义train session 和evaluate session,这些函数用来定义在一个epoch中如何进行模型训练和预测,train_session 如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29train_op = model_spec['train_op']
loss = model_spec['loss']
update_metrics = model_spec['update_metrics'] # loop over all dataset
summary_op = model_spec['summary_op']
metrics = model_spec['metrics']
global_step = tf.train.get_or_create_global_step() # get global train step
# Step2, initialize variables
sess.run(model_spec['metrics_init_op']) # metrics op
sess.run(model_spec['iterator_init_op']) # iterator op
# Step3, loop train steps
# use tqdm trange as process bar
t = trange(num_steps)
for i in t:
# write summary after summary_steps
if i % params.save_summary_steps == 0:
_, loss_val, _, summary_val, step_val = sess.run([train_op, loss, update_metrics,
summary_op, global_step])
writer.add_summary(summary_val, step_val)
else:
_, _, loss_val = sess.run([train_op, update_metrics, loss])
t.set_postfix(loss='{:05.3f}'.format(loss_val))
# Step4 print metrics
metric_val_tensor = {k: v[0] for k, v in metrics.items()}
metric_vals = sess.run(metric_val_tensor)
metric_vals_str = ' ; '.join('{}: {:05.3f}'.format(k,v) for k, v in metric_vals.items())
logging.info('- Train Metrics: '+ metric_vals_str)对于代码详细内容请查看文件train_evaluate.py
inference
inference 模块是根据eval_session 函数改写而成方便单独做预测- train
train.py训练和预测主入口,训练流程,首先读取数据为datast,将dataset制作为模型所需要的iterator形式,再创建模型,创建model specification, 最后进行训练。模型参数
模型参数汇总如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19{
"test_size": 4584061,
"field_size": 39,
"train_size": 3667249,
"dev_size": 4584062,
"padding_value": 121640,
"feat_size": 121641,
"batch_size": 2048,
"epochs": 10,
"learning_rate": 0.001,
"buffer_size": 1,
"fm_dropout_keep": 1.0,
"dropout_keep_prob": 0.5,
"l2_reg": 0.1,
"embedding_size": 10,
"hidden_layers":"32,32",
"save_summary_steps": 10
}
效果评估
对算法进行测试,这里考察的指标是logloss和accuracy,目前训练阶段的logloss最低为0.4,acc为0.75,eval最好数据是logloss:1.5, acc:0.74. 测试结果来看,并未达到网上所说auc0.80的效果,logloss为0.4的结果。
另外一个问题整体模型GPU使用率特别低只有10%不到,需要提高并行性以提高性能。


评论加载中