主要工作
基于用户搜索query和对应的点击log,构建出三层的概念图谱,基于图谱对文档进行tagging,从而避免普通打标签粒度过细或过粗的情况。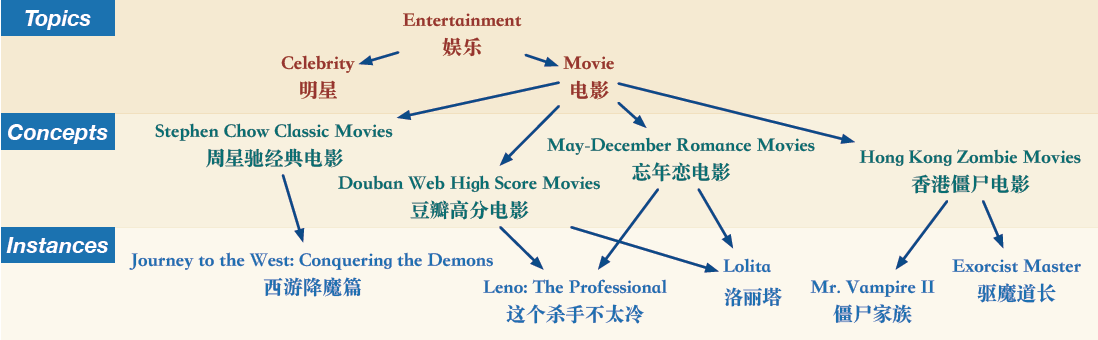
user-centered concept mining
目标构建用户为中心的concept概念图谱
从给定的query和query对应的点击内容当中,寻找一个word/phrase能够表示query和点击内容含义。形式化定义$q={w_1^qw_2^q\cdots w_{|q|}^q}$表示query,由词序列构成,query集合为$Q$,文档$t={w_1^tw_2^t\cdots w_{|t|}^t}$,同样有词序列构成,目标是提取概念短语$c={w_1^cw_2^c\cdots w_{|q|}^c}$,能够从语义层面表示query和点击title。
作者提出了三种方式来提取概念,整体框架图如下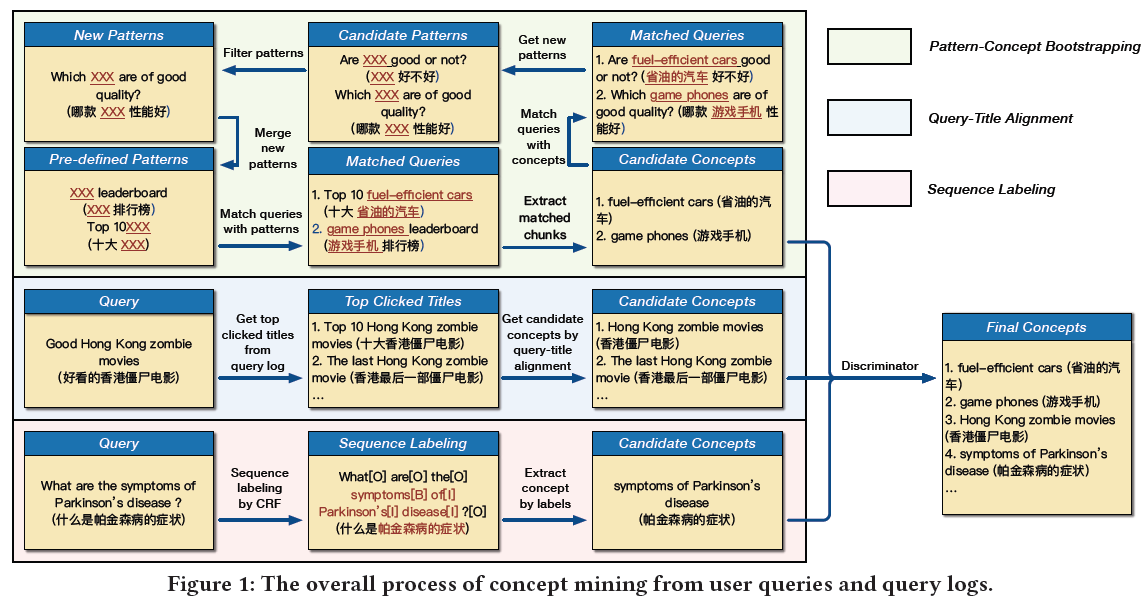
Bootstrapping by Pattern-Concept Duality
bootstrapping思想就“自助法”,结合当前的场景主要有两个,一是人工定义一些pattern,根据这些pattern可以从query集合中提出很多度concept,而是根据这些提取出concept的query集合又可以学习和总结出新的pattern,这样往复进行。为了保证提取出pattern的质量,需要对已经筛选出的pattern进行过滤,原则是一个pattern对应越多的query,则其价值或意义越低。定义$p$表示新生成的pattern,$n_s$表示基于规则$p$选出的且已经存在于种子集中的concept个数,$n_e$表示从query集合中提取出新concept的数量,筛选规则为1)$\alpha < \frac{n_s}{n_e} < \beta$ and 2) $n_s > \delta$,其中$\alpha=0.6,\beta=0.8,\delta=0.2$,如果pattern提取的结果满足以上规则则保留。此种方式的缺点,提取的concept数量有限Concept minning by query-title alignment
采用query和title对齐方式提取concept,原理是如果一个concept出现在query中,那么很大概率它也会出现在与这个query相关的已点击title中,比如query “香港最后一部僵尸电影”,“香港高校僵尸电影”和query “香港僵尸电影”。具体步骤如下:
1) 给定query q,选择出对应点击的title集合$T^q=\{t_1^q,t_2^q,\cdots,t_{|T^q|^q}\}$,点击次数N>5,D=30天
2) 对于q 和每个$t \in T^q$,枚举他们中的Ngram
3) 通过步骤2选择出query中从位置i开始长度为n的文本块$g_{in}^q=w_i^qw_{i+1}^q\cdots w_{i+n-1}^q$,从标题t中选择出位置从j开始长度为m的文本款$g_{jm}^t=w_j^tw_{j+1}^\cdots w_{j+m-1}^t,$如果文本块$g_{jm}^t$按照相同的顺序包含$g_{in}^q$中所有的词 或者$w_i^q=w_j^t,w_{i+n-1}^q=w_{j+m-1}^t$则把$g_{jm}^t$选为候选concept。
4) 文中没有提到候选的步骤,但是这种方式会提取出无意义的文本块,因此后面会添加一个分类器,来判断该候选是否适合作为conceptSupervised sequence labeling
前两种方式都是无监督方式,对这个问题可以采用序列标注方式进行处理,将concept看成需要标注的对象,类似于NER /POS这种方式。A Discriminator ofr quality control
通过以上方式提取出concept之后,需要对这些概念进行筛选,并不是所有的概念都需要保留,因此需要建立一个分类器来决定是否需要保留这些概念,通过对每个concept构建特征例如是否在query中出现,被搜索次数,被点击次数,之后采用GBDT和LR进行二分类,保留的称作positive,未保留的成为negative,这些样本手工创建,训练分类器。
Concept Tagging
通过已构建的概念体系,可以对document进行tagging,标注上没有显式出现的concept,整个问题可以描述如下,
给定文档$d$,概念集合$C=\{c_1, c_2,\cdots, c_{|C|}\}$,需要解决的是从概念集合中寻找出与文档$d$相关的概念集合$C^{d}=\{c_1^{d}, c_2^{d}, \cdots, c_{|c^d|}^d\}$
论文中采用两种方式是进行提取概念,一种基于probablility inference 和matching based两种方式,对给文档进行tagging的流程如图所示,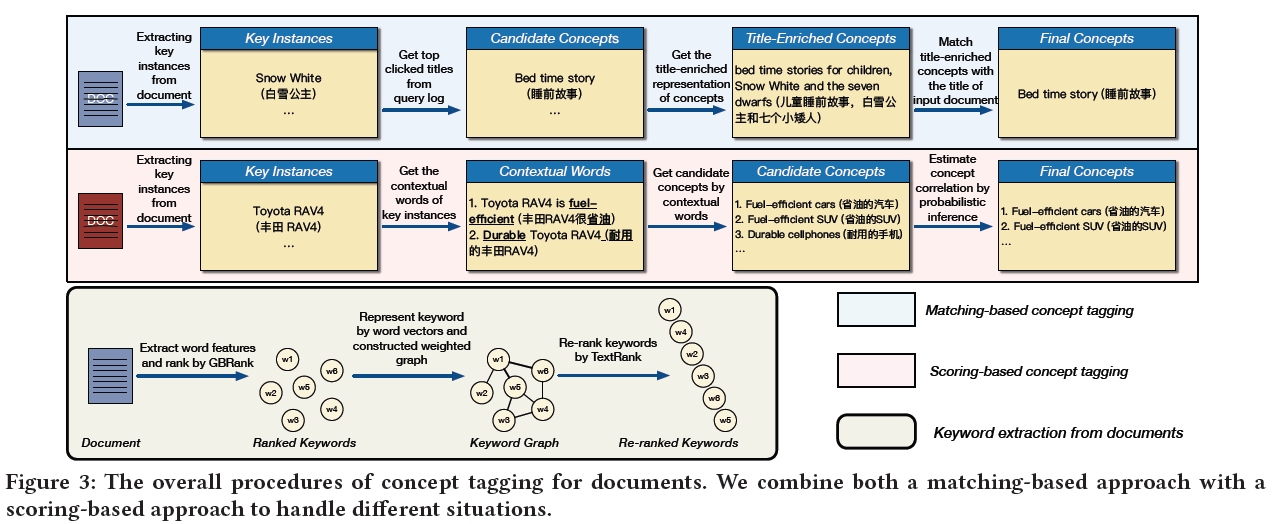
总体来说,文档concept的tagging过程,首先对文档提取key instance extraction,这里instance 从概念关系图谱中可以看到instance指代的是一些实体,之后对于能够与概念图谱中的概念建立isA的则直接利用matching选择候选concept,对于无法直接建立isA关系的concept则利用probability inference方式来选择候选实体,最终在对候选实体集合进行排序。
- Key instance extraction
首先基于词的TF、POS、NER等特征信息利用GBRank算法,对文档中的词进行排序;然后将每个词基于词向量表示成词向量,根据GBRank的排序结果选择TopK=10构建一个无向图有权图,权重为词向量间的cosine 距离;之后在利用TextRank算法对这些词进行排序,最后基于排序结果保留score大于$\delta_{w}=0.5$的关键词。这种结合RBRank,word vector和TextRank相结合的方式,提取出的关键词与文档主题具有更高的相关性和逻辑性。 Concept tagging by probabilistic inference
基于概率推理的概念concept tagging处理步骤如下:其中,$p(c|d)$表示给定文档$d$属于概念$c$的概率,$E^d$表示已从文档中提取出的instance集合,$p(e_i^{d}|d)$表示给定文档$d$含有关键词或instance概率,论文中解释为 the document frequence of instance $e_i^d \in E^d$。(其实这里有点想不通,问什么是文档频率,这个文档是指文档d,我更倾向于将它理解为词频)$p(c|e_i^d)$表示给定关键词或instance属于概念$c$的概率,总体来看,一个文档属于某个概念的概率主要有两方面的因素构成,一方面是该文档含有该关键词的概率即关键词在文档中的重要性,另一方面是关键词属于概念的概率即关键词对概念的贡献度,二者结合起来推断文档所对应的概念。
这里会另外一种情况,提取出的instance和概念$c$直接不存在isA的关系,此时利用关键词上下文的词来进行处理,
其中,$p(x_j|e_i^d)$表示上下文词$x_j$和$e_i^d$贡献的概率,文中定义上下文词和instance出现在同一个句子中则视为贡献,$X_{E^d}$为从文档d中提取出的共现词的集合,$p(c|x_j)$表示共现词是概念$c$子串的概率,定义如下
其中$C^{X_j}$表示含有词$x_j$为子串的概念集合
这样一来,对于没有建立isA关系的概念,通过上下文词来寻找概念。
文中举了一个例子,对于“丰田RAV4”可能没有直接与概念图谱里面建立关系,但是可以找到与他共现的词“省油”,“耐用”关键词,通过这些可以找到概念“省油的汽车”和“耐用的手机”,从而可以计算出该文档对应的概念。- Concept tagging by matching
首先来说明concept和instance这种isA的关系是如何建立和发现的,一方面给定一个concept,可以收集到很多具有相同修饰语的用户queries和点击titles,然后从这些queries/titles中提取instances,然后利用公式$p(c|e)=\sum_{j=1}^{X_{E^d}}p(c|x_j)p(x_|e_i^d)$来找到后续的instance,例如文中的例子,通过概念“省油的汽车”,可以检索到很多query/titles类似“省油的丰田RAV4”,从而可以从中提取instance“丰田RAV4”;
对于匹配的方式,首先利用instance提取的方式,已经提取出$E^d=\{e_1^d, e_2^d,\cdots, e_{E^d}^d\}$集合,通过匹配找到概念集合$C=\{c_1^d, c_2^d, \cdots, c_{|C_d|}^d\}$
对于每个概念c利用点击量topN=5的titles来扩充每个概念的表示,然后将文档$d$和概念$c$都采用TF-IDF表示成向量,计算二者的cosine相似度,只保留大于$\delta_u=0.58$,对于这种方式,概念和关键词对,和每个概念扩充后的表示都可以事先计算好,来提高计算效率。
应用
Query rewriting for Searching
对用户输入的query进行改写,具体是如果query能够与概念图谱中的某个概念$c$建立isA联系,则将概念c对应的instance依次与query进行拼接,组成新的query-> “q e”进行检索,结果显示此种方式能有效提高检索结果的相关性。
Recommendation
在建立了概念图谱之后,用户和内容都可以具有topic,concept, instance标签,通过这些做召回和CTR,结果显示在点击率和停留时间上都有明显提升。从另一方面,也说明概念更能够理解内容和用户潜在感兴趣的东西。


评论加载中